

The Chatbot with RAG
- Time frame: 05/2024 - 07/2024
- Project URL: Chatbot
- Team: Noah Hartmann
- Core Technologies/Frameworks/Tools: Python, LangChain, HuggingFace, DeepEval, Streamlit
About
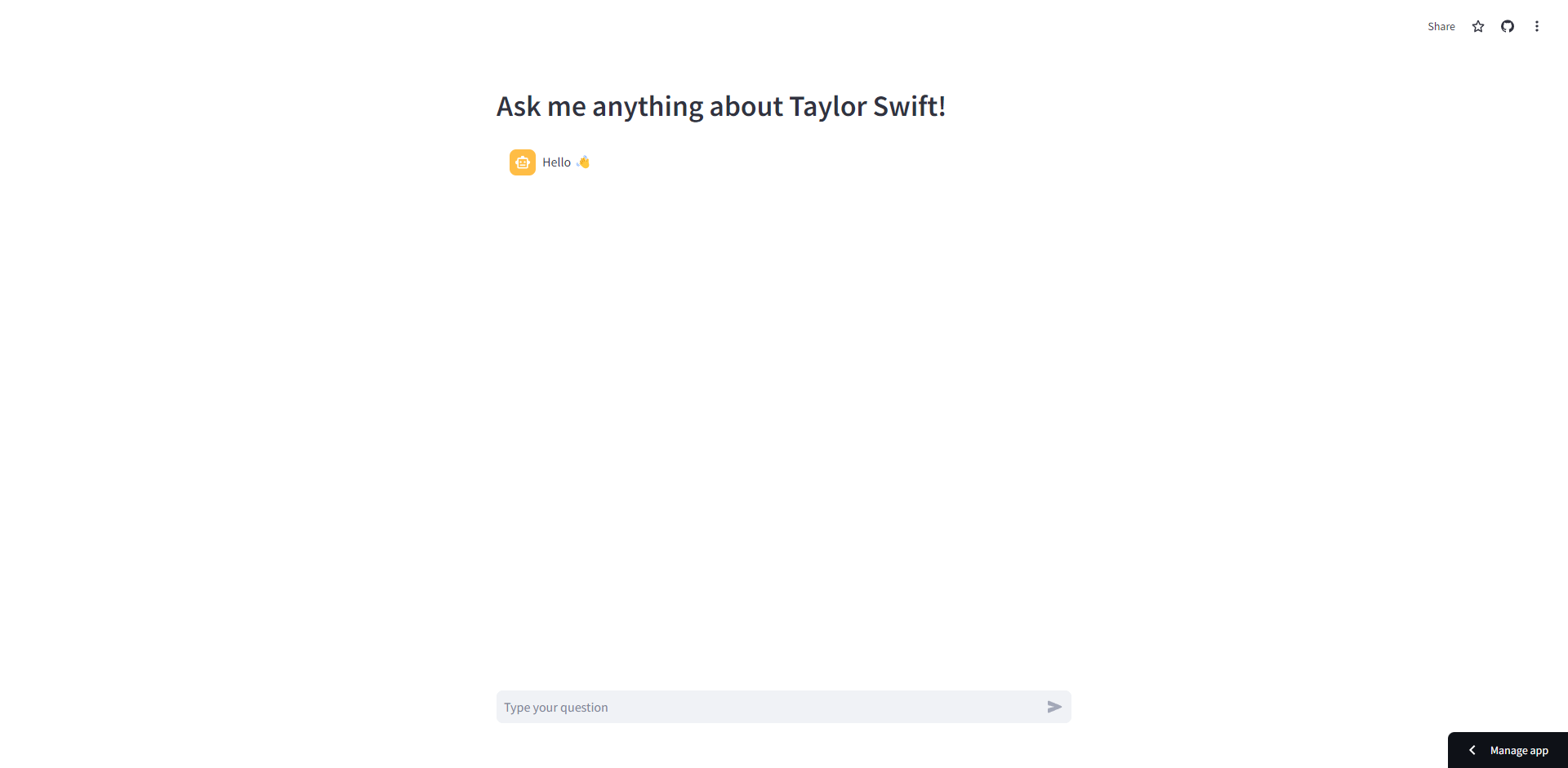
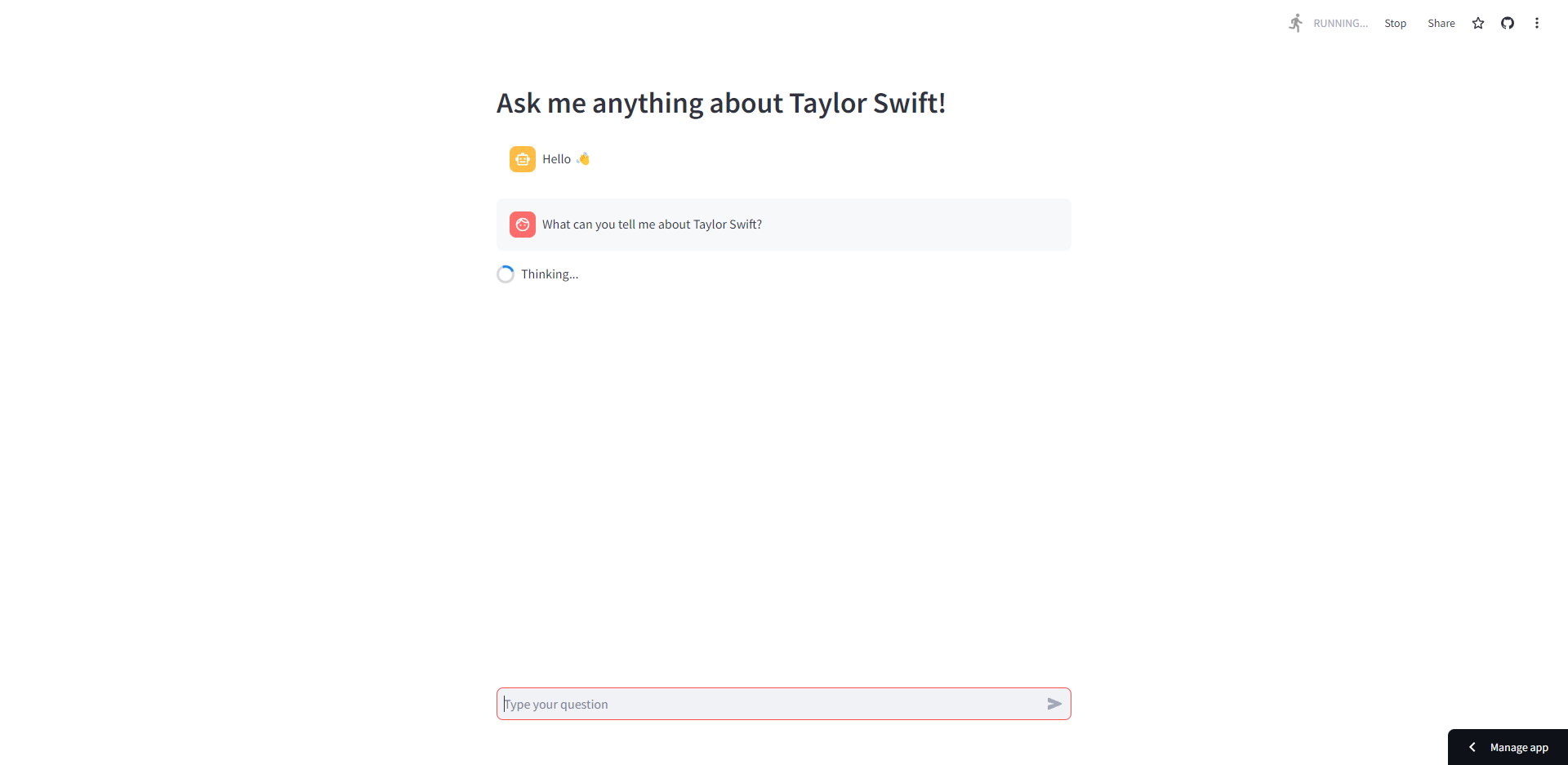
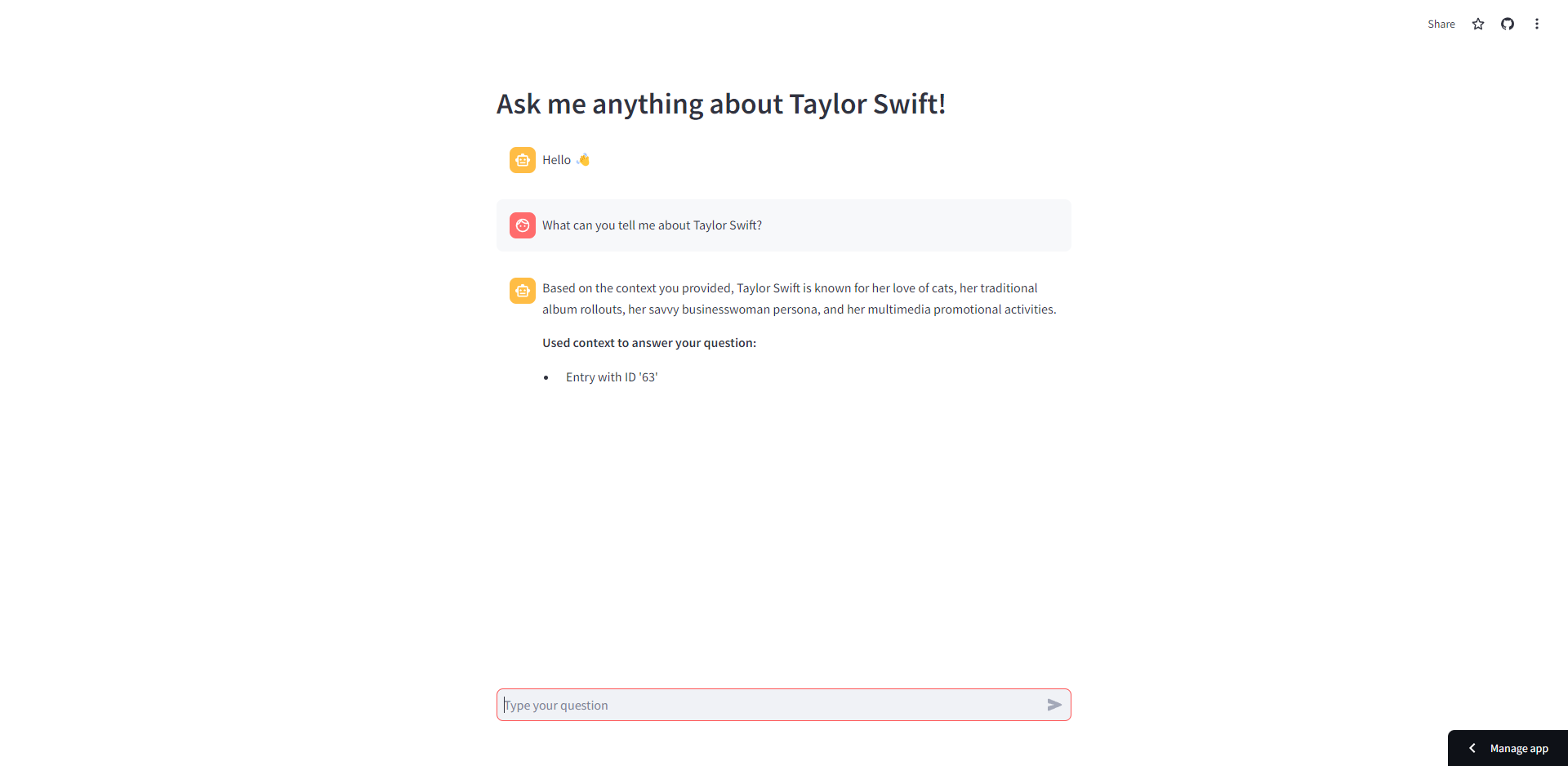
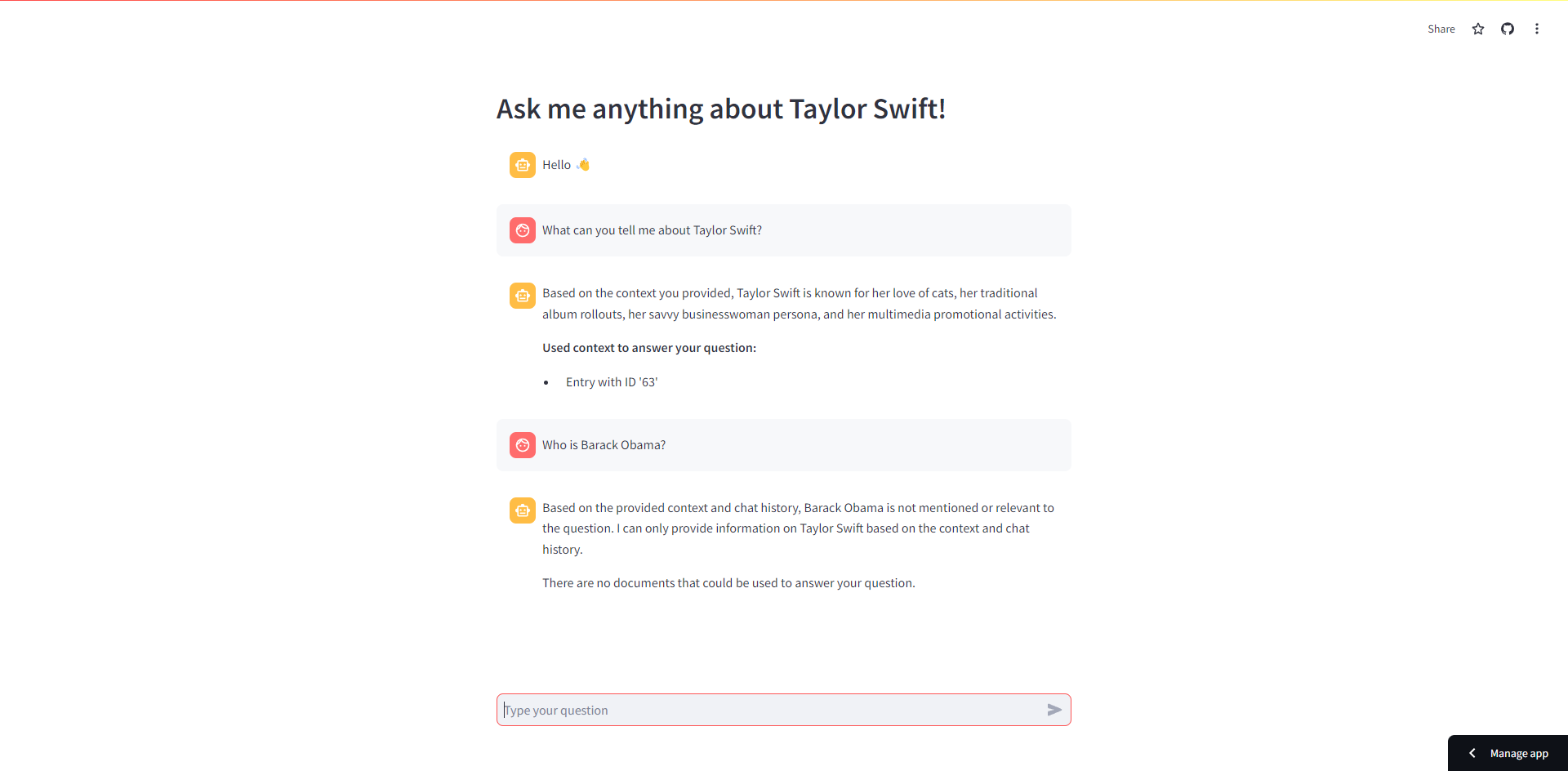
As part of the elective course "Artificial Intelligence and Adaptive Systems", a chatbot application with Retrieval Augmented Generation (RAG) pipeline has been developed. It can answer questions regarding Taylor Swift.
A detailed report (in German) can be found here.
Retrieval Augmented Generation
Retrieval-Augmented Generation (RAG) is an architectural concept designed to enhance the efficiency of Large Language Model (LLM) applications by utilizing custom data. This approach involves retrieving relevant data or documents related to a question or task and using this information as context for the LLM.RAG combines two key components:
- Retrieval System: It searches for relevant external information.
- Generation Model: It uses this retrieved information to generate accurate and contextually appropriate responses.
- Hallucination: RAG reduces the likelihood of the LLM generating plausible but incorrect information by incorporating up-to-date and verified external data. This helps mitigate issues like sentence contradictions, factual inaccuracies, and irrelevant outputs.
- Out of Date: Traditional LLMs may provide outdated information due to their training data. RAG addresses this by ensuring that the model has access to the latest and most reliable information through the retrieval step.
- Lack of Source Attribution: RAG allows users to trace the sources of the information provided by the LLM, thereby enhancing transparency and trustworthiness.
Combining Fine-Tuning with RAG can significantly improve LLMs. Fine-Tuning refines models for specific domains using targeted data, while RAG enhances accuracy by integrating current external information.
For applications that do not require specialized domain knowledge (like this little chatbot), implementing a RAG architecture alone may be sufficient.
The application was implemented and evaluated using
- Python (v3.12)
- LangChain (v0.2.7)
- Hugging Face
- Streamlit (v1.36.0)
- Deepeval (v0.21.65)
- Set Top-k and Chunk Size differently
- Using a Re-Ranker
- Using a more advanced retriever
- ...
Screen Capture
My responsibilities
As I developed the application alone, I was responsible for all tasks.
I started by researching the RAG architecture and the tools & components needed to implement it.
Needed and used components:
- Dataset for filling the vector database
- Library for data preprocessing - used Pandas
- Text splitter for dividing long texts into smaller, usable segments
- An embeddings model for converting text files into vectors
- A chat model for generating responses
- A vector store
- A retriever for searching and retrieving relevant documents from the vector database
- Suitable prompt templates for structuring queries to the language model
- Suitable chains for linking various processing steps in the RAG process
- A Frontend
- Contextual Precision Metric
- Contextual Recall Metric
- Contextual Relevancy Metric
- Answer Relevancy Metric
- Faithfulness Metric
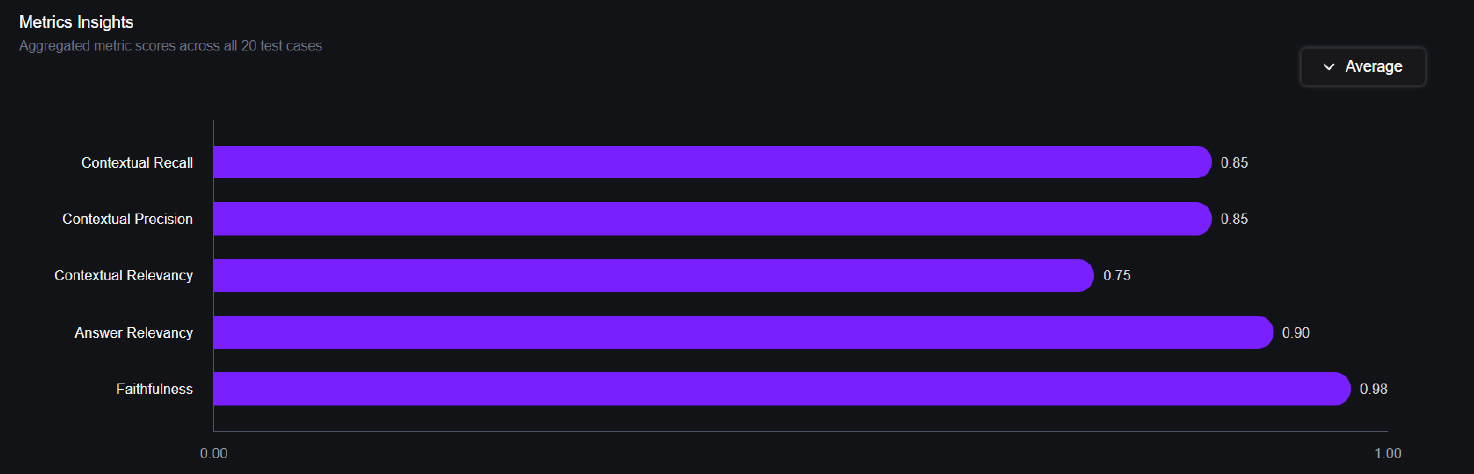
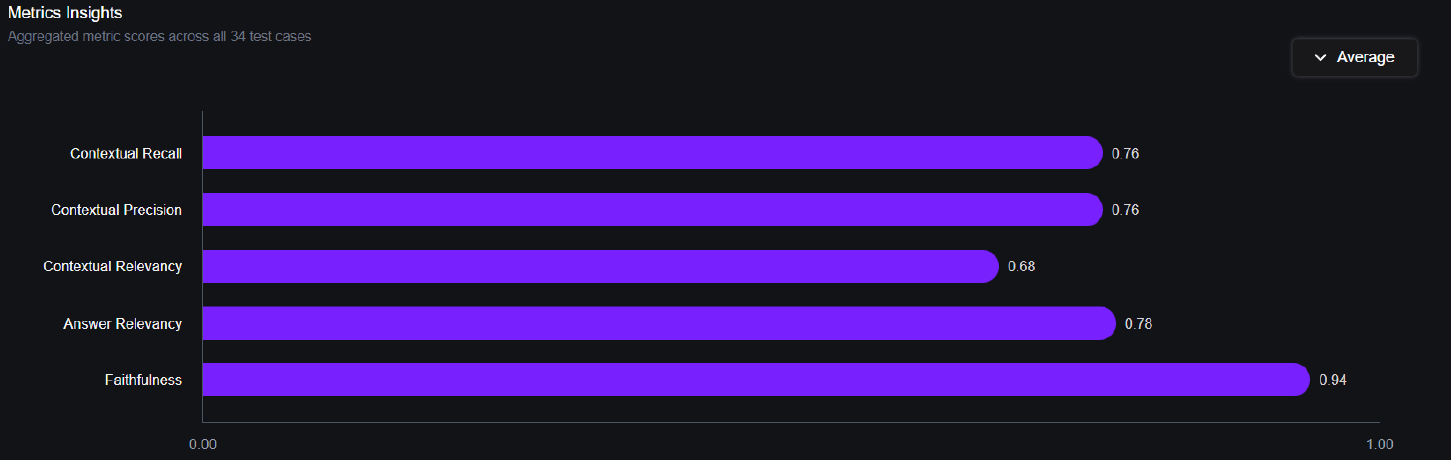
- Chunk Size of the Text Splitter: Chunks may be too large, including irrelevant information, or too small, missing important context.
- Adjustment of Top-K: The number of returned results may not be ideal—too many results might include irrelevant information, while too few might miss relevant information.
Learnings
- Importance of Prompt Engineering: Initially, the retriever returned many irrelevant documents. I improved this by refining data preprocessing and experimenting with parameters like Top-K and threshold. However, the generated answers were still partially incorrect. Trying different LLMs and embedding models like Cohere didn’t help. The solution was adjusting the prompt templates to provide better instructions to the model, leading to more relevant responses.
- Significance of Dataset Selection: The originally chosen dataset, "Netflix Movies and TV Shows," was unsuitable for evaluation due to the lack of factual questions. Consequently, I had to find a new dataset and adjust the data preprocessing towards the end of the project.
- Challenges in Formulating Standalone Questions: There were difficulties in creating a standalone question from chat history and a new query. Often, comments were added instead of rephrasing the original question. Inappropriate context sometimes led to unsuitable answers, affecting the rephrasing of standalone questions. Multiple variants of a question were also generated instead of a single reformulated question.
- Lessons on Dataset Usage: Initially, I used a subset of the dataset, which made it easier to manage and understand the process. However, I later realized that I had worked with only a fraction of the original dataset and neglected to use the full set. When I updated the vector database with the complete dataset, the quality of the RAG pipeline significantly decreased. This suggests that the data preprocessing worked well for the small subset but was inadequate for the entire dataset.
I suspect that improvements in both the retriever and the prompt template are needed to optimize this process. Due to time constraints, I opted for a different approach. Instead of reformulating user prompts based on chat history, the prompts are now revised by an LLM before the retrieval step to make the queries as precise as possible without considering previous context.